|
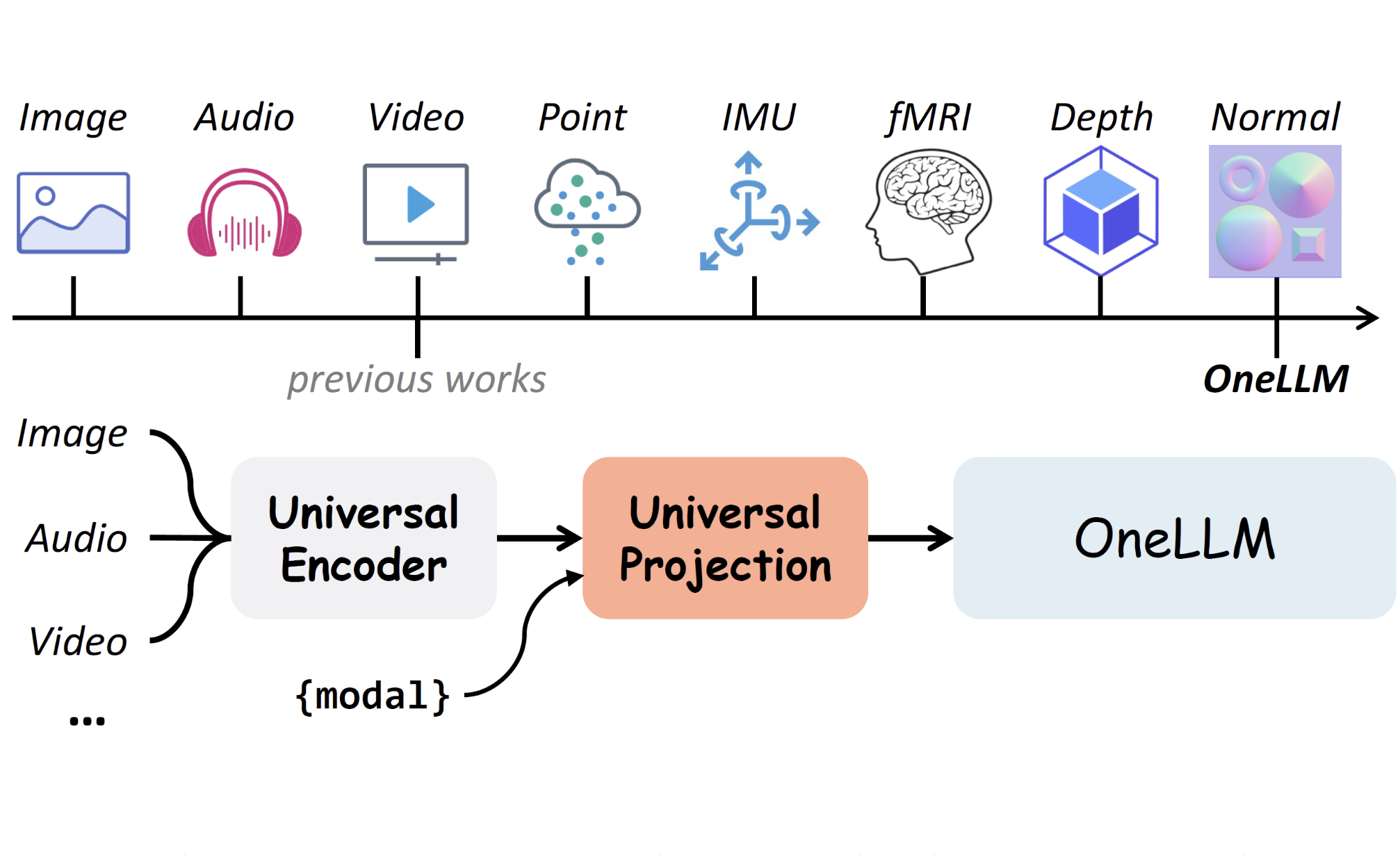
OneLLM: One Framework to Align All Modalities with Language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao,
Peng Gao, Xiangyu Yue
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2024
PDF |
Project |
Code |
Demo |
BibTex
|
|
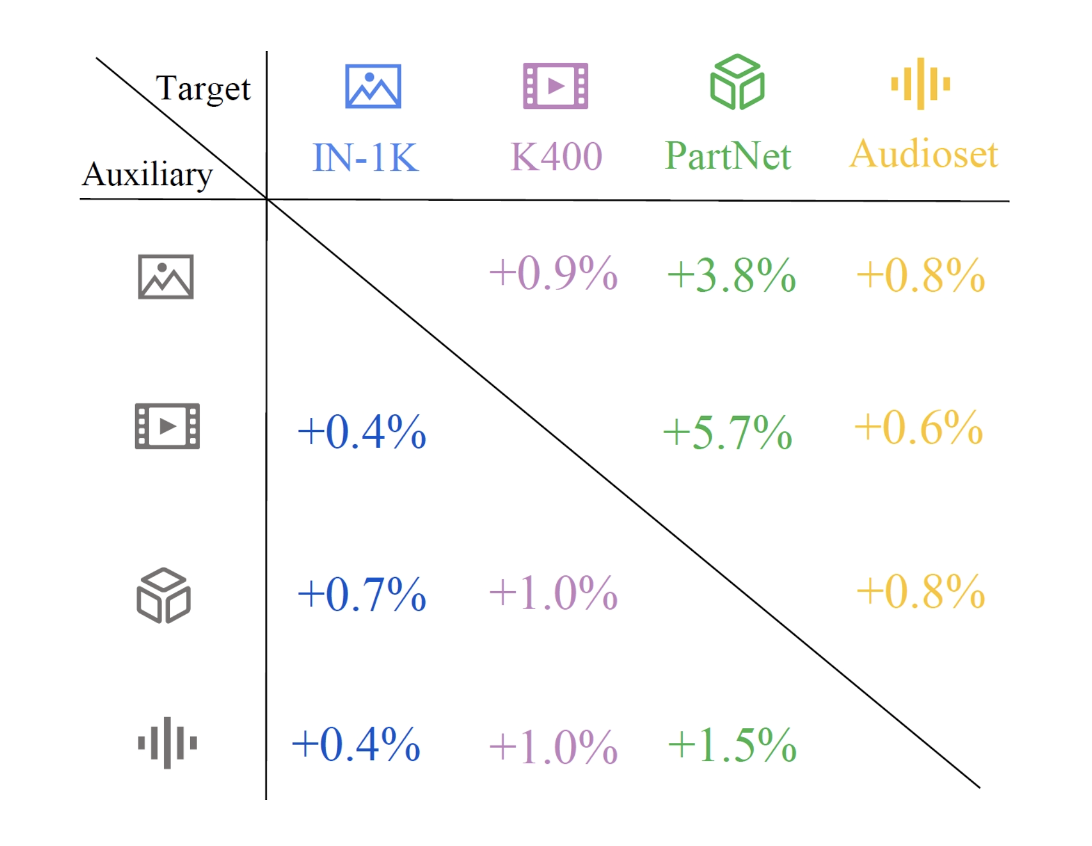
Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities
Yiyuan Zhang, Xiaohan Ding, Kaixiong Gong, Yixiao Ge, Ying Shan, Xiangyu Yue
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2024
PDF |
Project |
Code |
BibTex
|
|
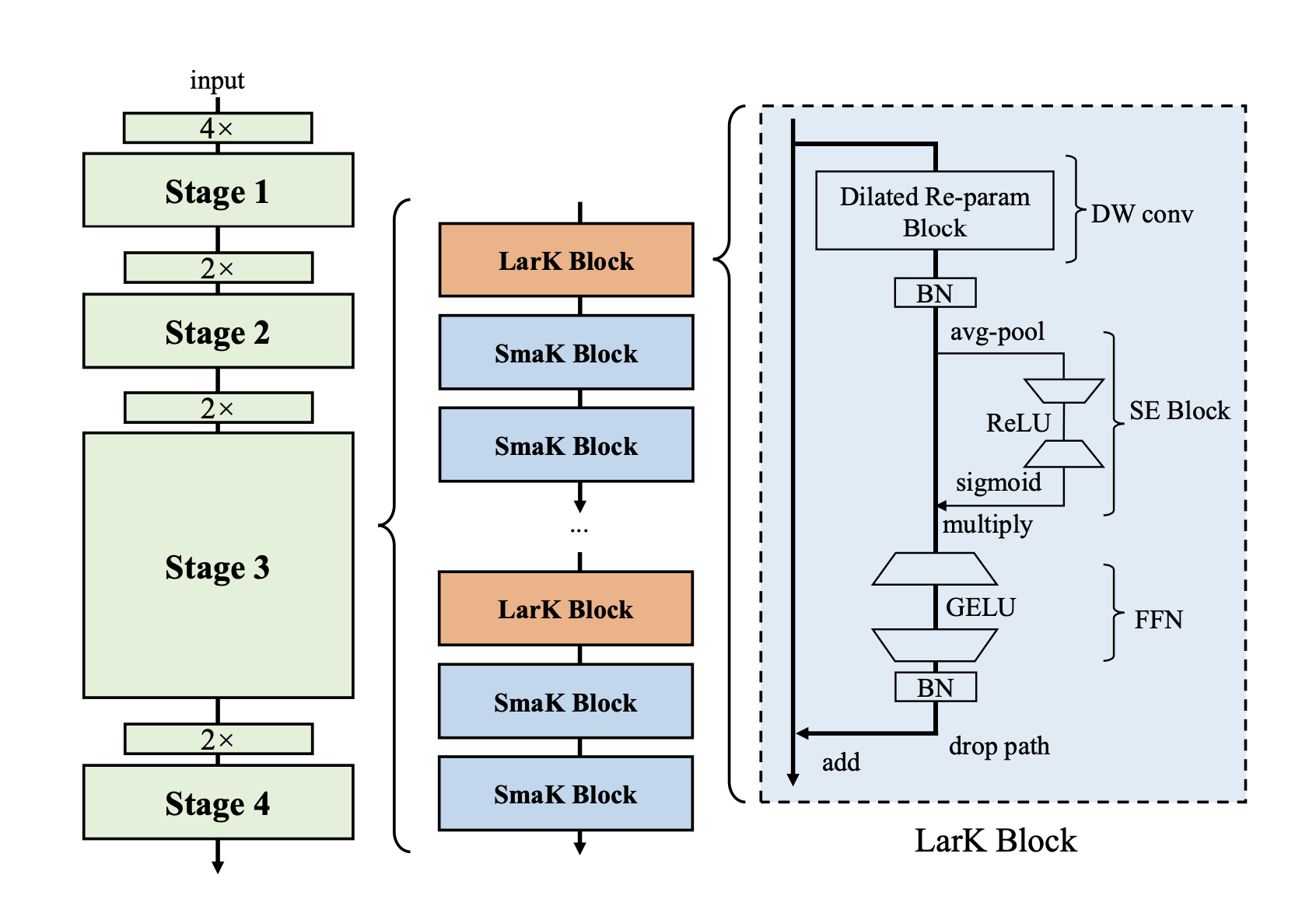
UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition
Xiaohan Ding, Yiyuan Zhang, Yixiao Ge, Sijie Zhao, Lin Song, Xiangyu Yue, Ying Shan
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2024
PDF |
Project |
Code |
BibTex
|

|
Meta-Transformer: A Unified Framework for Multimodal Learning
Yiyuan Zhang, Kaixiong Gong, Kaipeng Zhang, Hongsheng Li, Yu Qiao, Wanli Ouyang, Xiangyu Yue
Preprint 2023
PDF |
Project |
Code |
BibTex
|
|
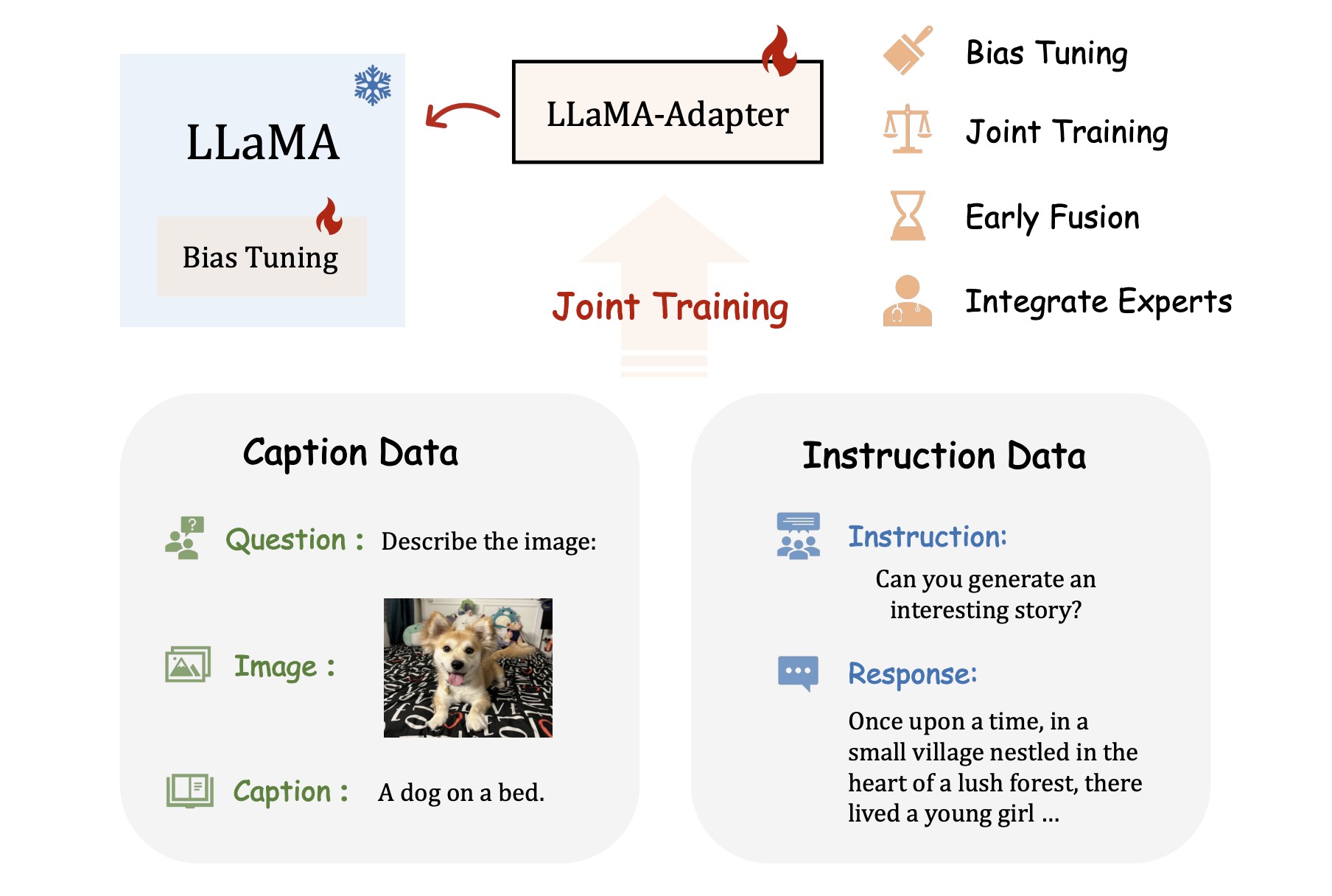
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, Hongsheng Li, Yu Qiao
Preprint 2023
PDF |
Code |
BibTex
|
|
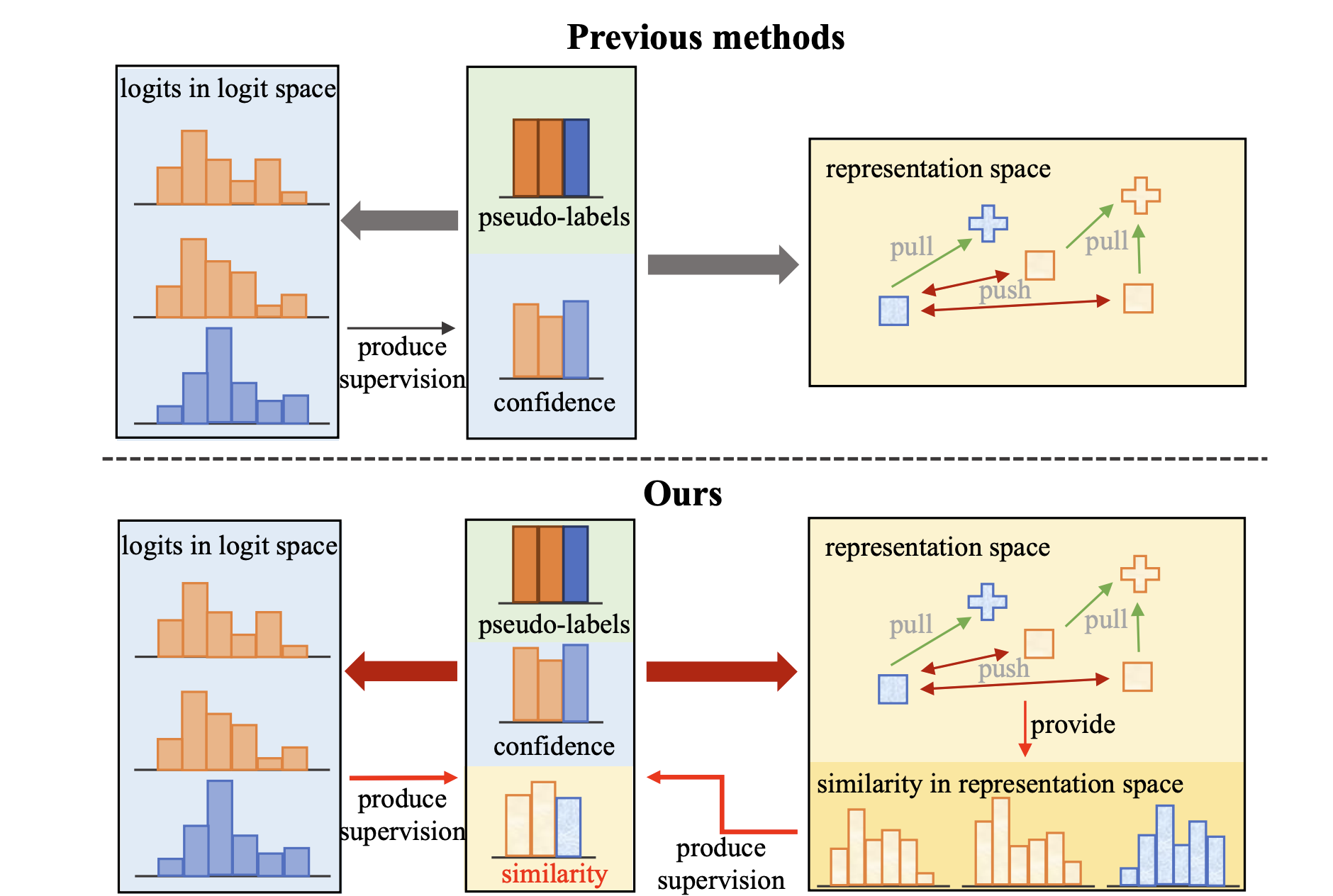
Space Engage: Collaborative Space Supervision for Contrastive-based Semi-Supervised Semantic Segmentation
Changqi Wang, Haoyu Xie, Yuhui Yuan, Chong Fu, Xiangyu Yue
International Conference on Computer Vision (ICCV) 2023
PDF |
Code |
BibTex
|
|
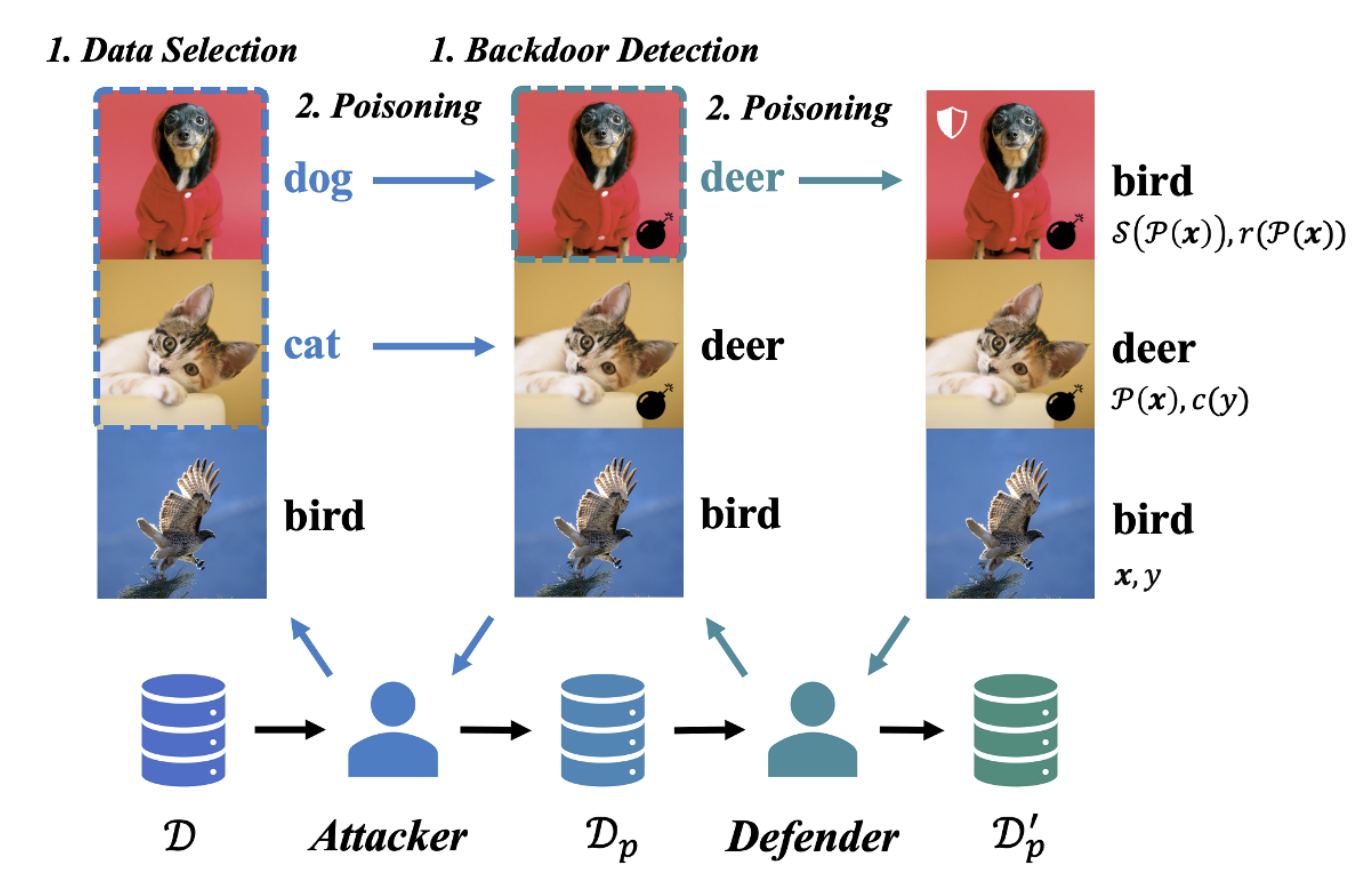
Beating Backdoor Attack at Its Own Game
Min Liu, Alberto Sangiovanni-Vincentelli, Xiangyu Yue
International Conference on Computer Vision (ICCV) 2023
PDF |
Code |
BibTex
|
|
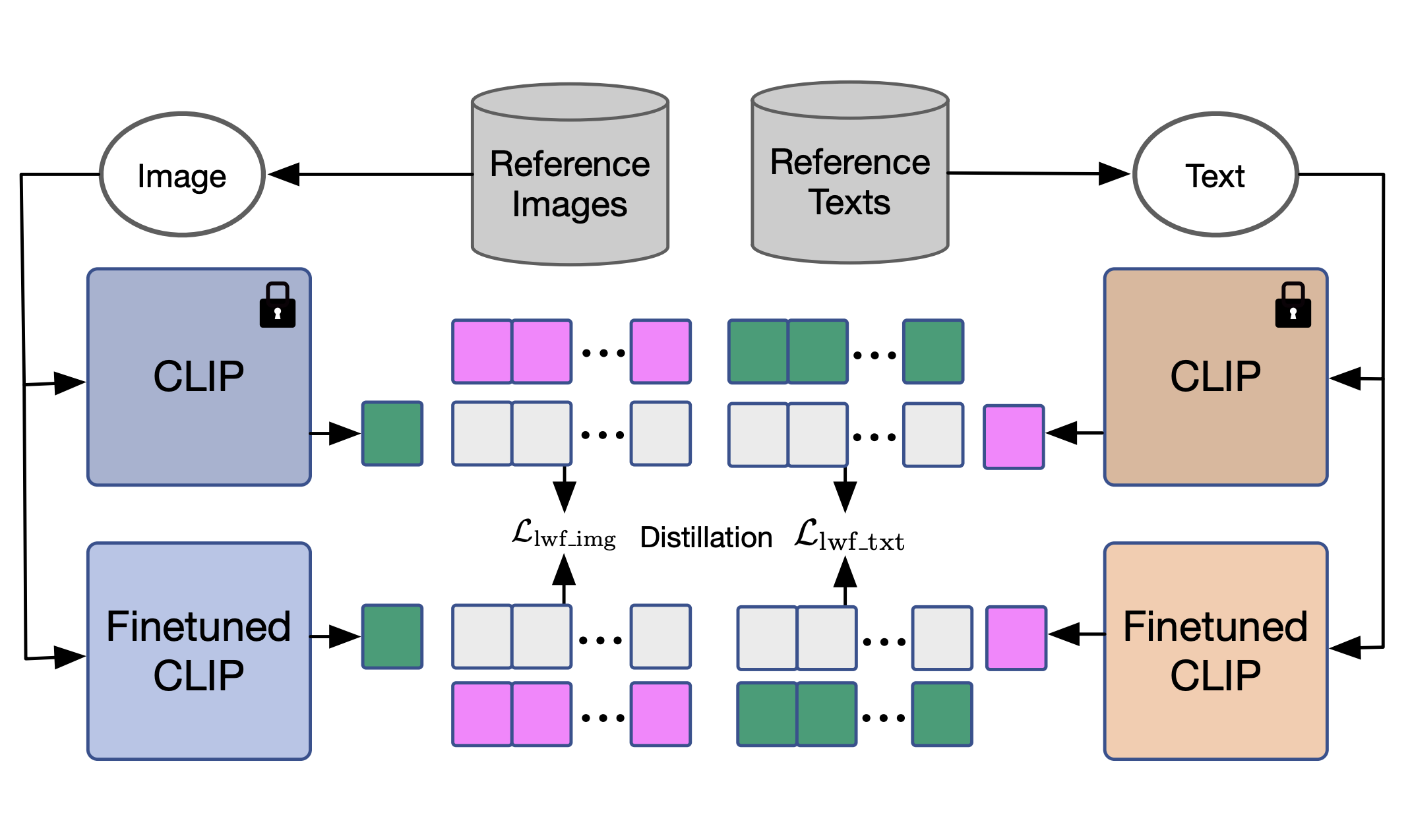
Preventing Zero-Shot Transfer Degradation in Continual Learning of Vision-Language Models
Zangwei Zheng, Mingyuan Ma, Kai Wang, Ziheng Qin, Xiangyu Yue, Yang You
International Conference on Computer Vision (ICCV) 2023
PDF |
Code |
BibTex
|
|
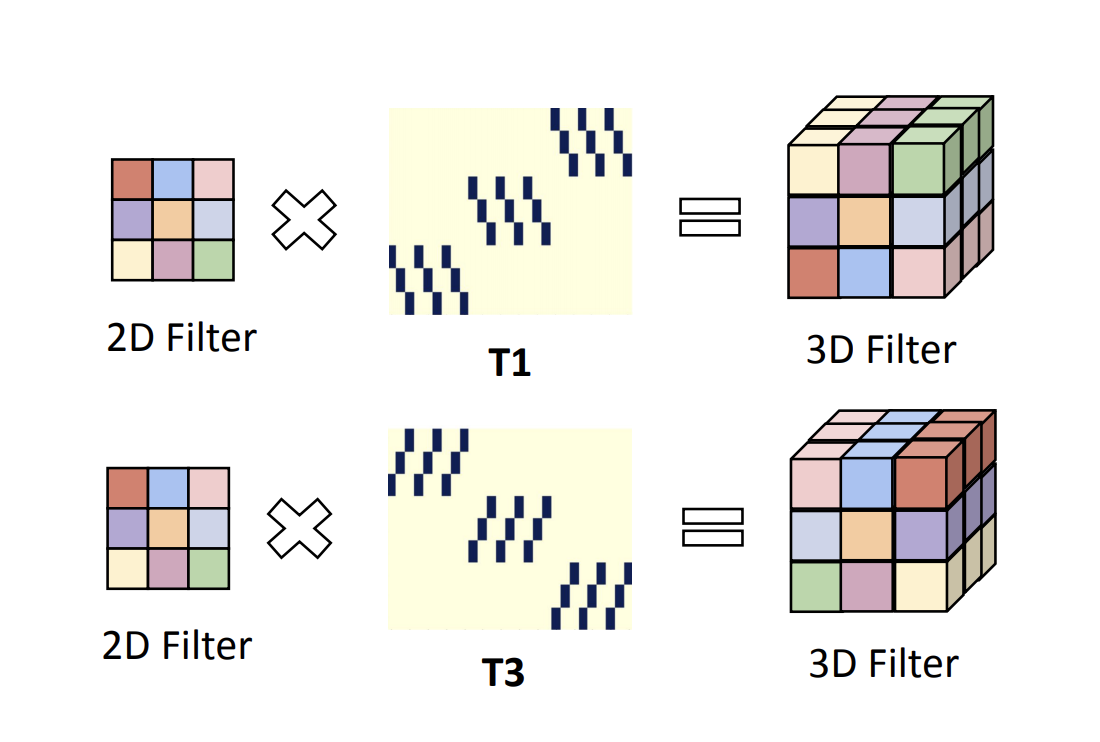
Image2Point: 3D Point-Cloud Understanding with 2D Image Pretrained Models
Chenfeng Xu, Shijia Yang, Tomer Galanti, Bichen Wu, Xiangyu Yue, Bohan Zhai, Wei Zhan, Kurt Keutzer, Peter Vajda, Masayoshi Tomizuka
European Conference on Computer Vision (ECCV) 2022
PDF |
Code |
BibTex
|
|
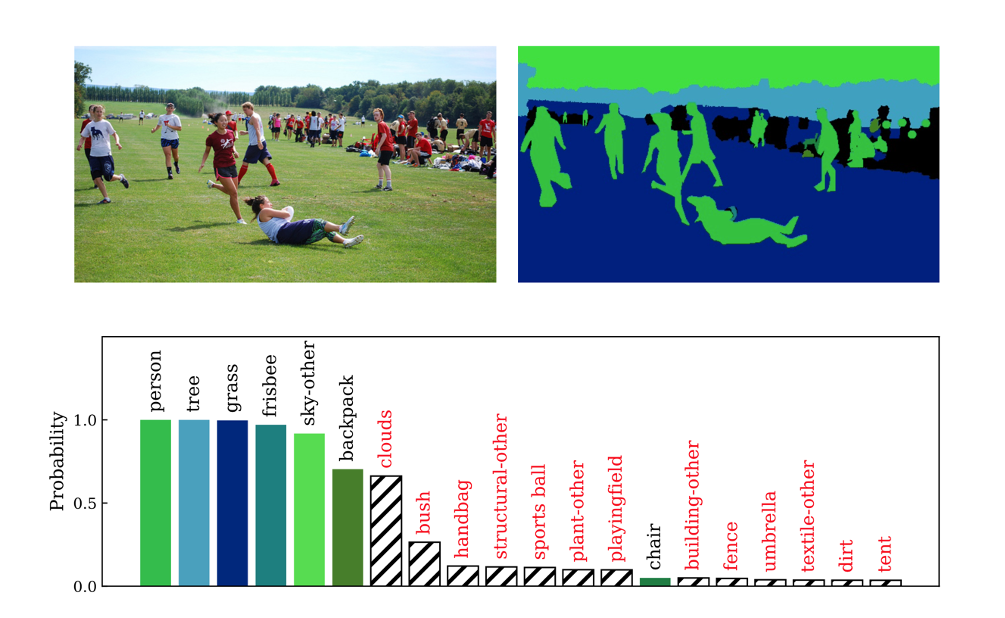
MLSeg: Image and Video Segmentation as Multi-Label Classification and Selected-Label Pixel Classification
Haodi He, Yuhui Yuan, Xiangyu Yue, Han Hu
European Conference on Computer Vision (ECCV) 2022
PDF |
Code |
BibTex
|
|
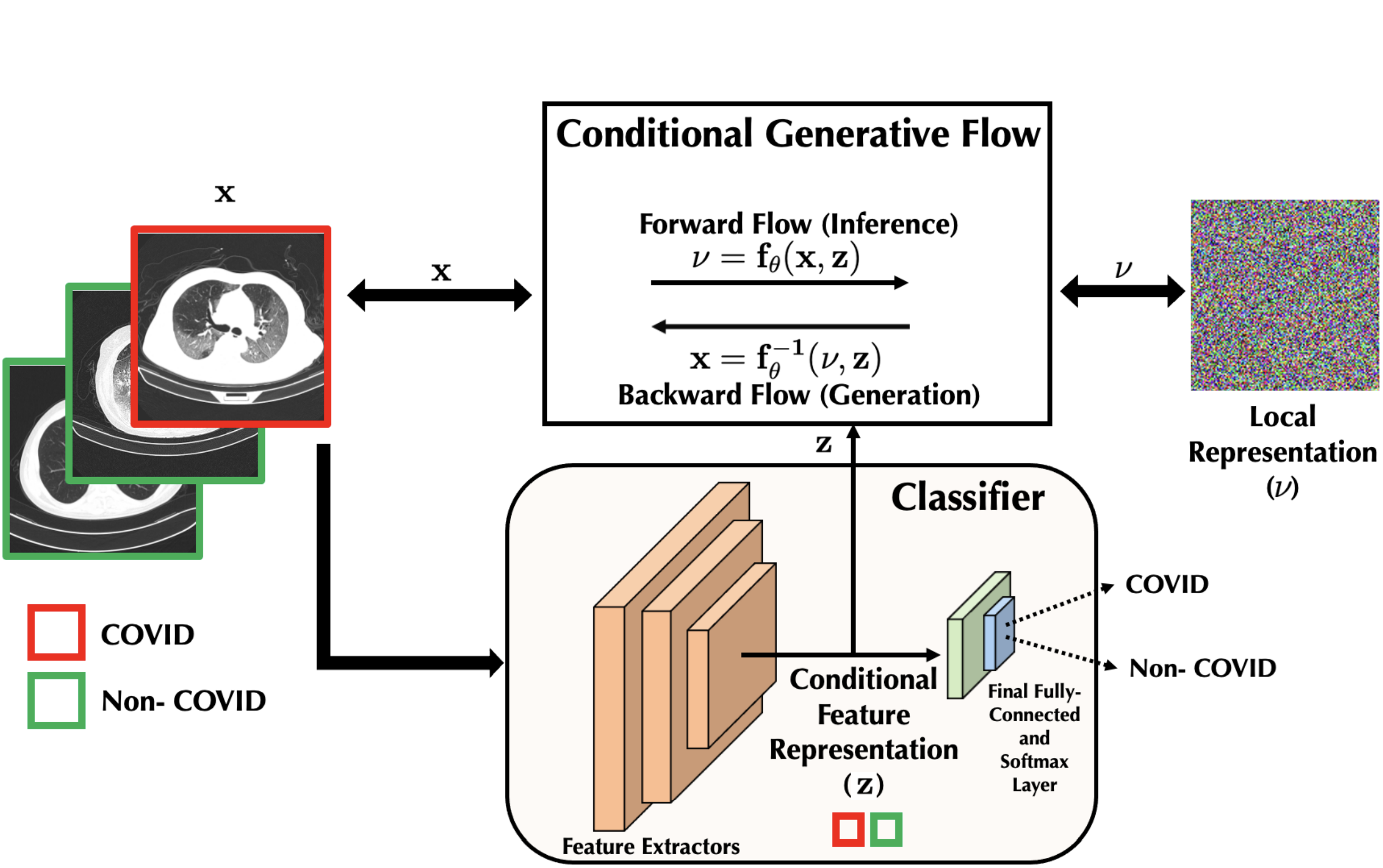
Conditional Synthetic Data Generation for Robust Machine Learning Applications with Limited Pandemic Data
Hari P. Das, Ryan Tran, Japjot Singh, Xiangyu Yue, Geoff Tison, Alberto Sangiovanni Vincentelli, Costas Spanos
AAAI Conference on Artificial Intelligence (AAAI), 2022
PDF |
BibTex
|
|
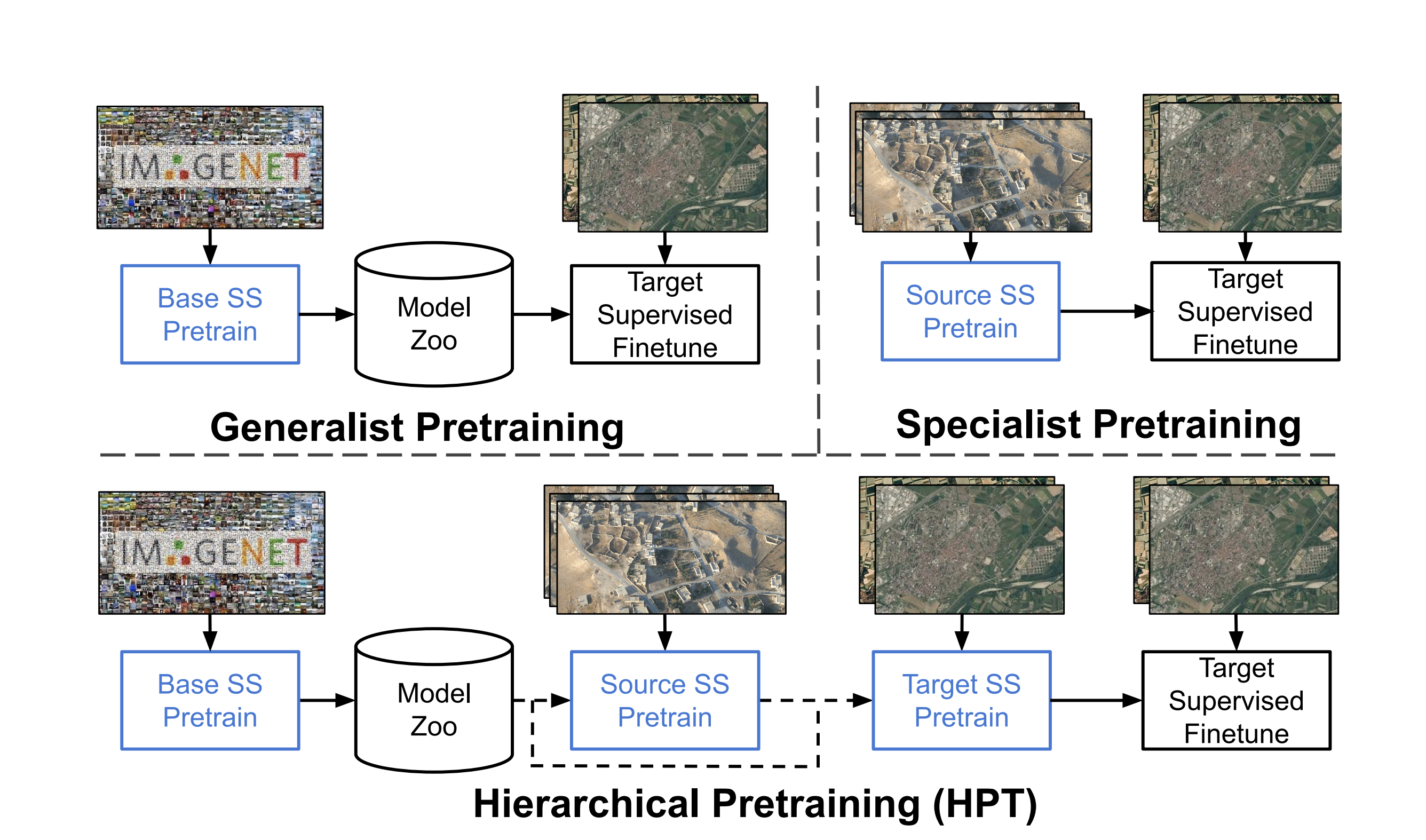
Self-Supervised Pretraining Improves Self-Supervised Pretraining
Colorado Reed*, Xiangyu Yue*, Ani Nrusimha, Sayna Ebrahimi, Vivek Vijaykumar, Richard Mao, Bo Li, Shanghang Zhang, Devin Guillory, Sean Metzger, Kurt Keutzer, Trevor Darrell
(* indicates equal contribution)
Winter Conference on Applications of Computer Vision (WACV) 2022
PDF |
Code |
BibTex
|
|
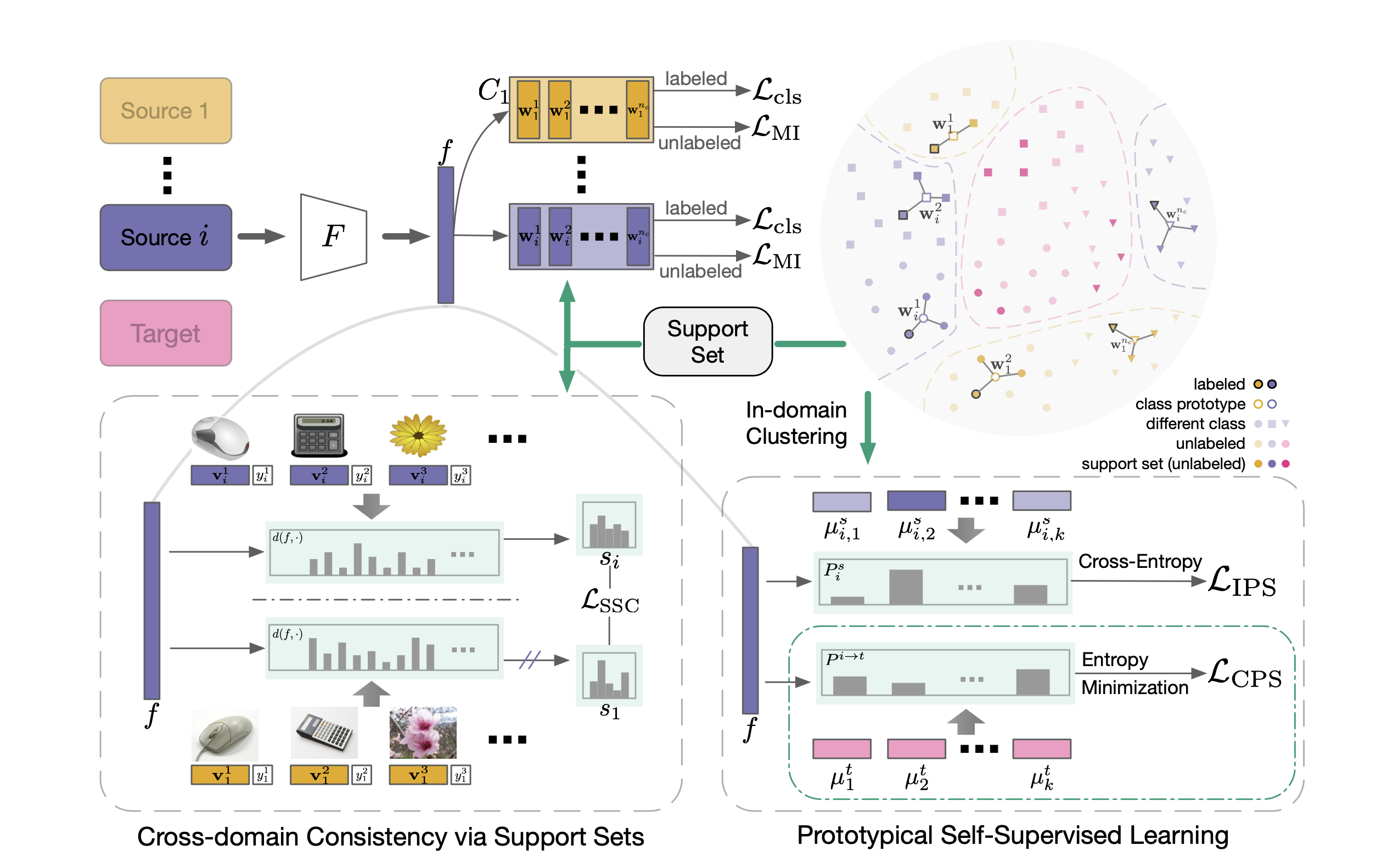
Multi-source Few-shot Domain Adaptation
Xiangyu Yue, Zangwei Zheng, Colorado Reed, Hari Prasanna Das, Kurt Keutzer, Alberto Sangiovanni Vincentelli
Preprint 2021
PDF |
Code to come |
BibTex
|
|
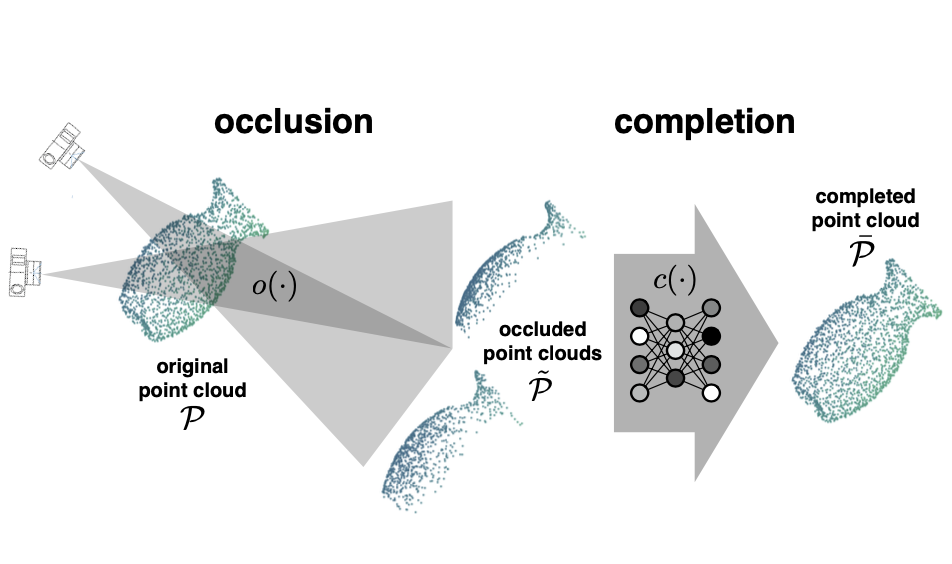
Unsupervised Point Cloud Pre-Training via View-Point Occlusion, Completion
Hanchen Wang, Qi Liu, Xiangyu Yue, Joan Lasenby, Matthew J. Kusner
International Conference on Computer Vision (ICCV), 2021
PDF |
Code |
BibTex
|
|
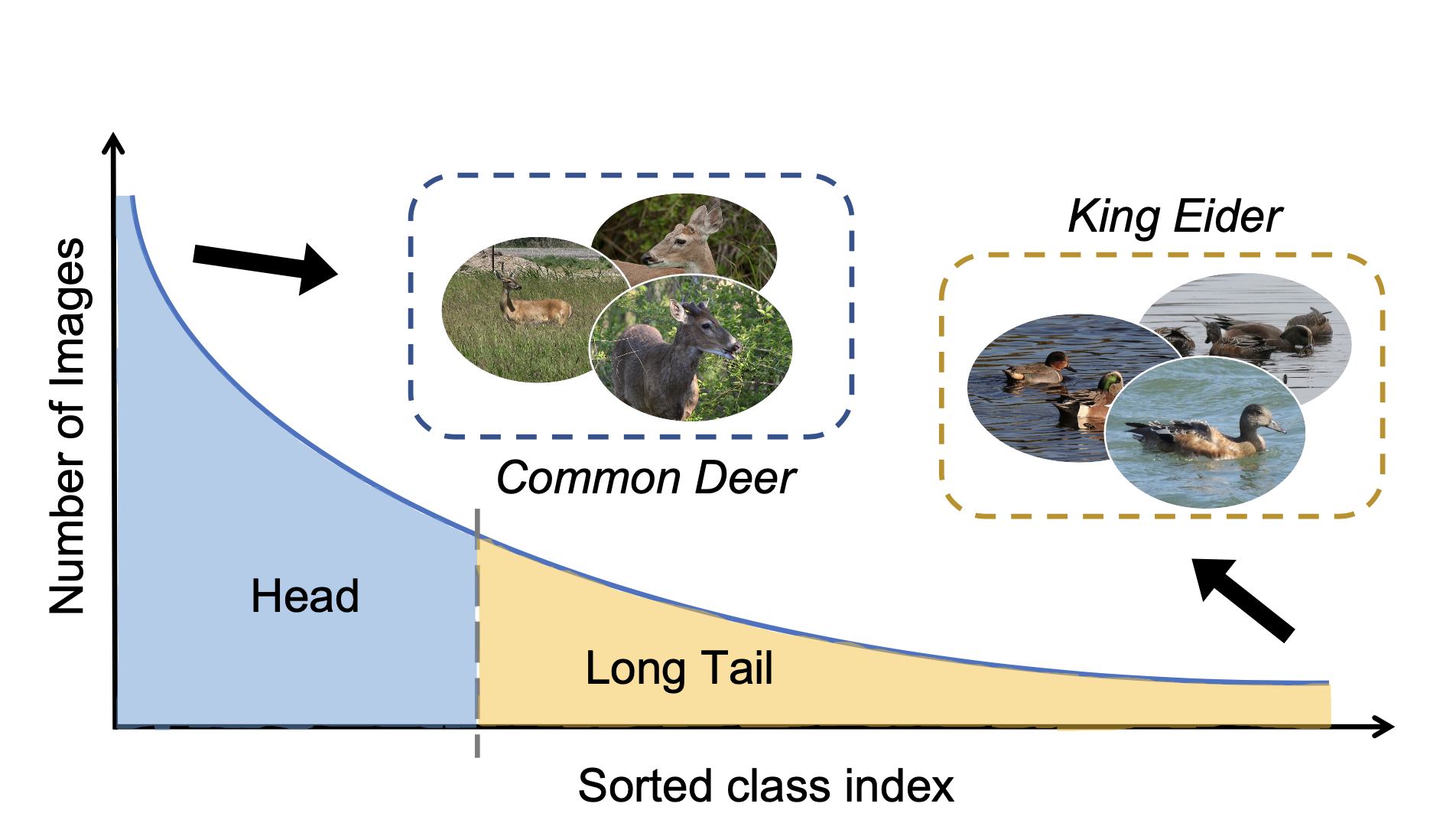
On Ensemble Methods for Long-Tailed Recognition
Xiangyu Yue, Yang Zhang, Zhewei Yao, Sicheng Zhao, Kurt Keuzer, Alberto Sangiovanni Vincentelli, Boqing Gong
Preprint 2021
PDF |
Code to come |
BibTex
|
|
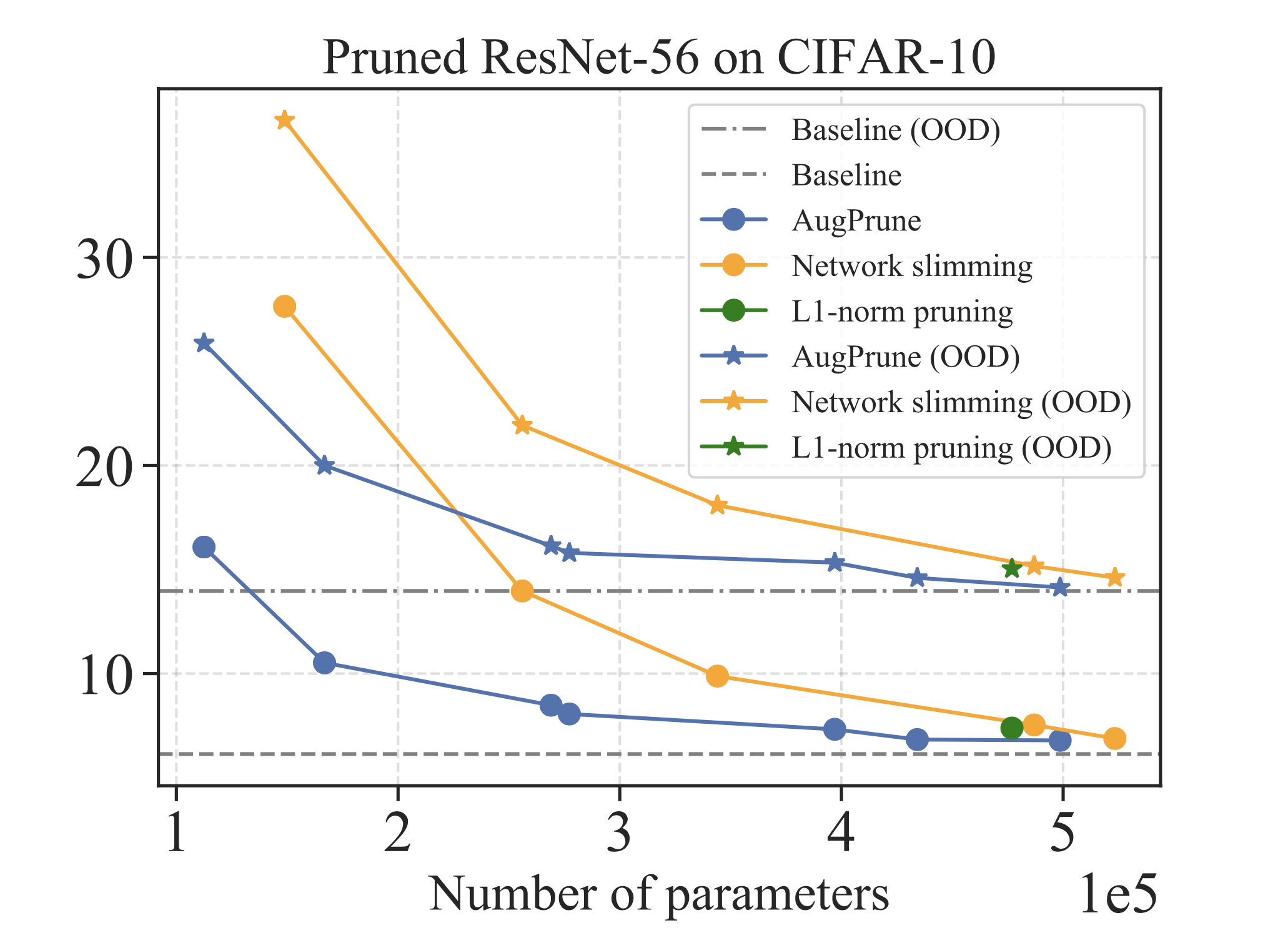
AugPrune: Robust Network Pruning via Augmented Data
Alex Zhao, Yaoqing Yang, Xiangyu Yue, Zhuang Liu, Elicia Ye, Michael Mahoney, Ramchandran Kannan, Joseph Gonzalez, Kurt Keutzer
Preprint 2021
PDF |
Code to come |
BibTex
|
|
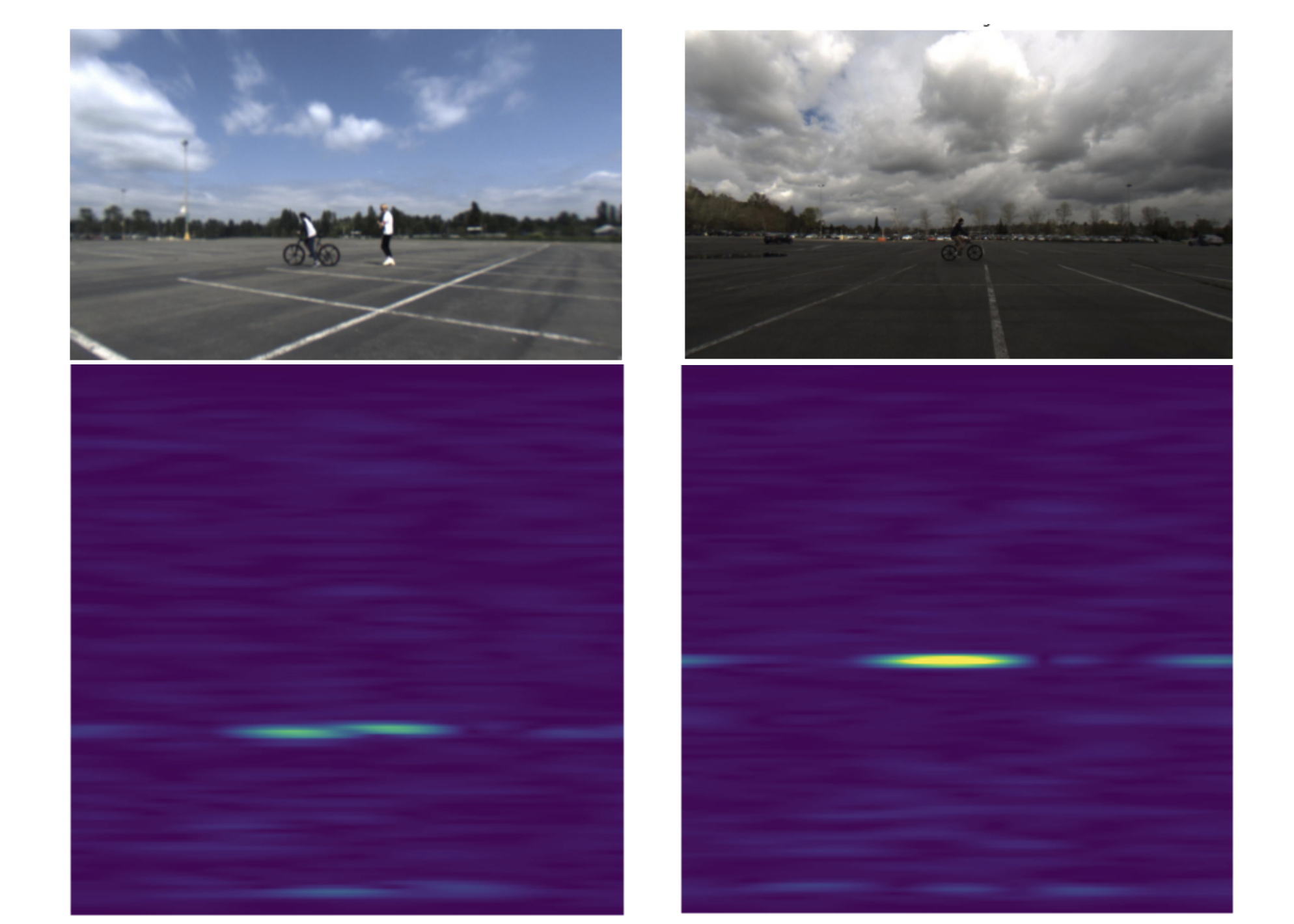
Scene-aware Learning Network for Radar Object Detection
Zangwei Zheng, Xiangyu Yue, Kurt Keutzer, Alberto Sangiovanni Vincentelli
International Conference on Multimedia Retrieval (ICMR) 2021
PDF |
BibTex
|
|
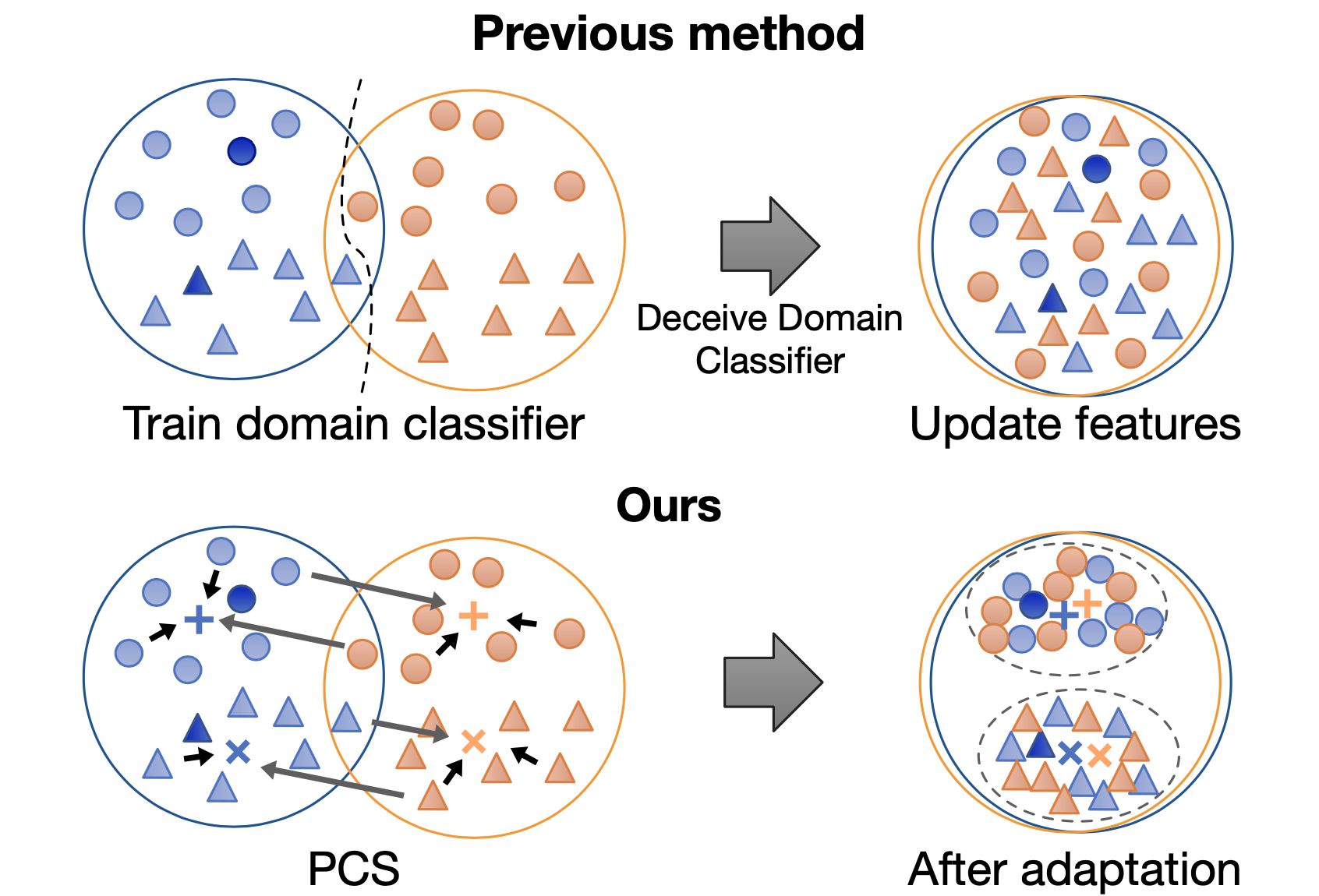
Prototypical Cross-domain Self-supervised Learning for Few-shot Unsupervised Domain Adaptation
Xiangyu Yue*,
Zangwei Zheng*,
Shanghang Zhang,
Yang Gao,
Trevor Darrell,
Kurt Keutzer,
Alberto Sangiovanni-Vincentelli (* indicates equal contribution)
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021
PDF |
Website |
Code |
Video |
Poster |
BibTex
|
|
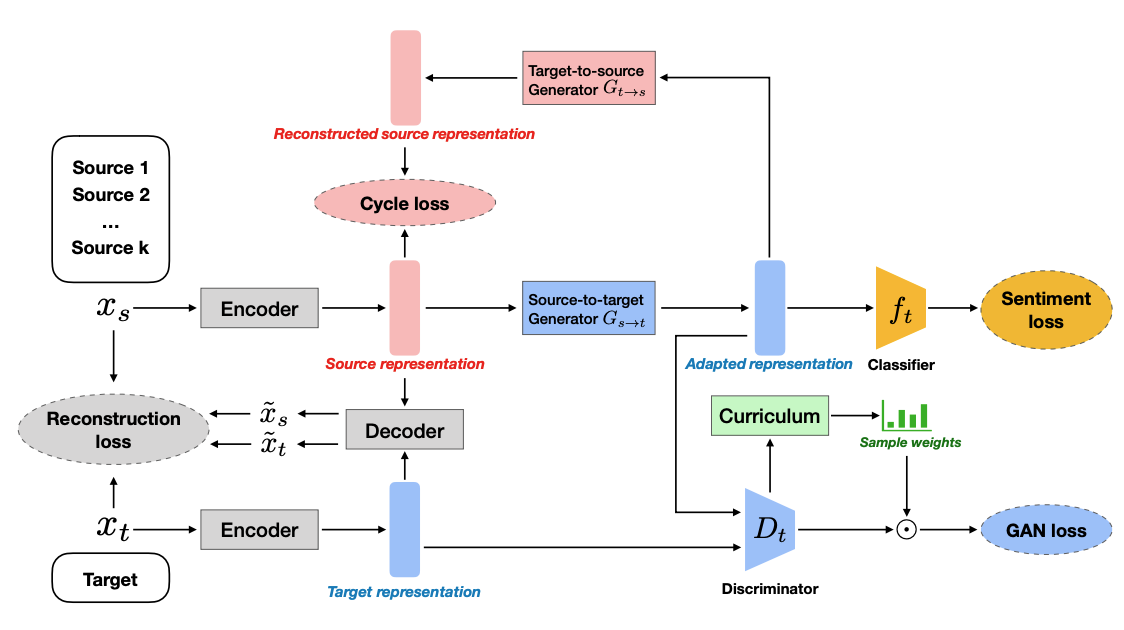
Curriculum Cyclegan for Textual Sentiment Domain Adaptation with Multiple Sources
Sicheng Zhao*,
Yang Xiao*,
Jiang Guo*,
Xiangyu Yue*,
Jufeng Yang, Ravi Krishna, Pengfei Xu, Kurt Keutzer
(* indicates equal contribution)
The Web Conference (WWW) 2021
PDF |
Code |
BibTex
|

|
Emotional Semantics-preserved and Feature-aligned CycleGAN for Visual Emotion Adaptation
Sicheng Zhao,
Xuanbai Chen,
Xiangyu Yue,
Chuang Lin, Pengfei Xu, Ravi Krishna, Jufeng Yang, Guiguang Ding, Alberto Sangiovanni-Vincentelli, Kurt Keutzer
IEEE Transactions on Cybernetics (TCYB) 2021
PDF |
BibTex
|
|
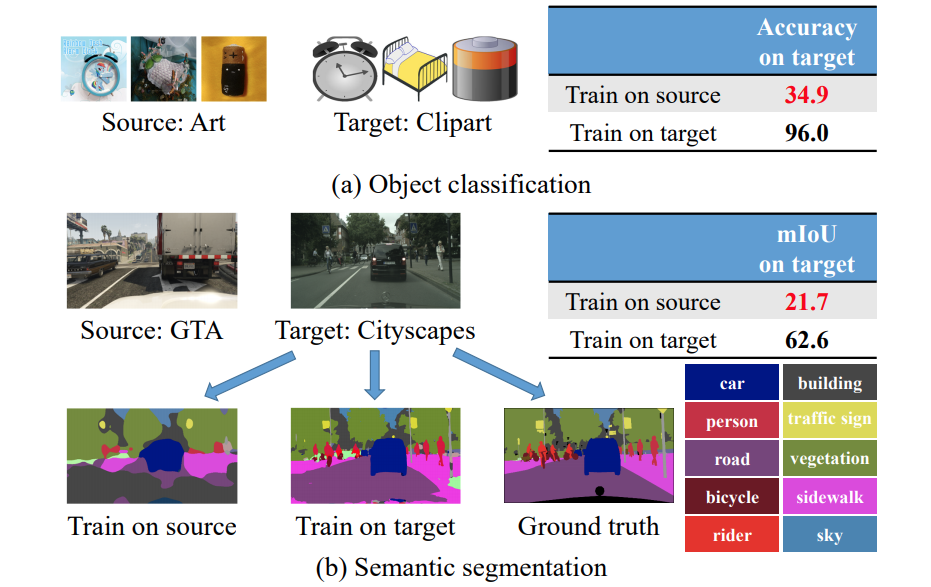
A Review of Single-Source Deep Unsupervised Visual Domain Adaptation
Sicheng Zhao,
Xiangyu Yue#,
Shanghang Zhang, Bo Li, Han Zhao, Bichen Wu, Ravi Krishna, Joseph E Gonzalez, Alberto L Sangiovanni-Vincentelli, Sanjit A Seshia, Kurt Keutzer (# indicates corresponding author)
IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2020
PDF |
BibTex
|
|
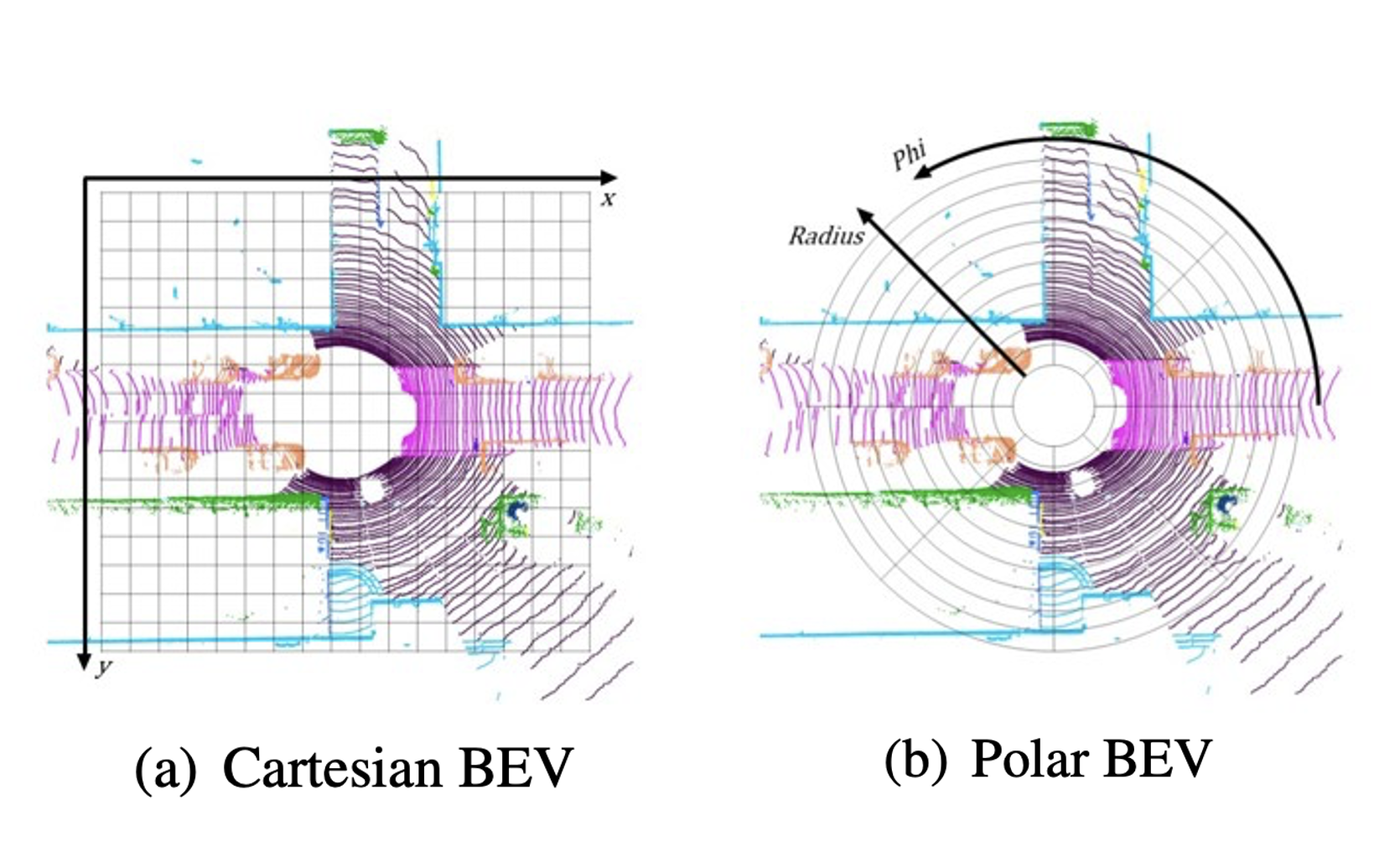
PolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation
Yang Zhang, Zixiang Zhou, Philip David,
Xiangyu Yue,
Zerong Xi, Boqing Gong, Hassan Foroosh
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020
PDF |
Code |
BibTex
|

|
Scenic: a Language for Scenario Specification and Scene Generation
Daniel J Fremont,
Xiangyu Yue*,
Tommaso Dreossi*, Shromona Ghosh*, Alberto L Sangiovanni-Vincentelli, Sanjit A Seshia (* indicates equal contribution)
ACM Conference on Programming Language Design and Implementation (PLDI) (2019)
PDF |
Code (Scenic) |
Code (Scenic2GTA) |
BibTex
|
|
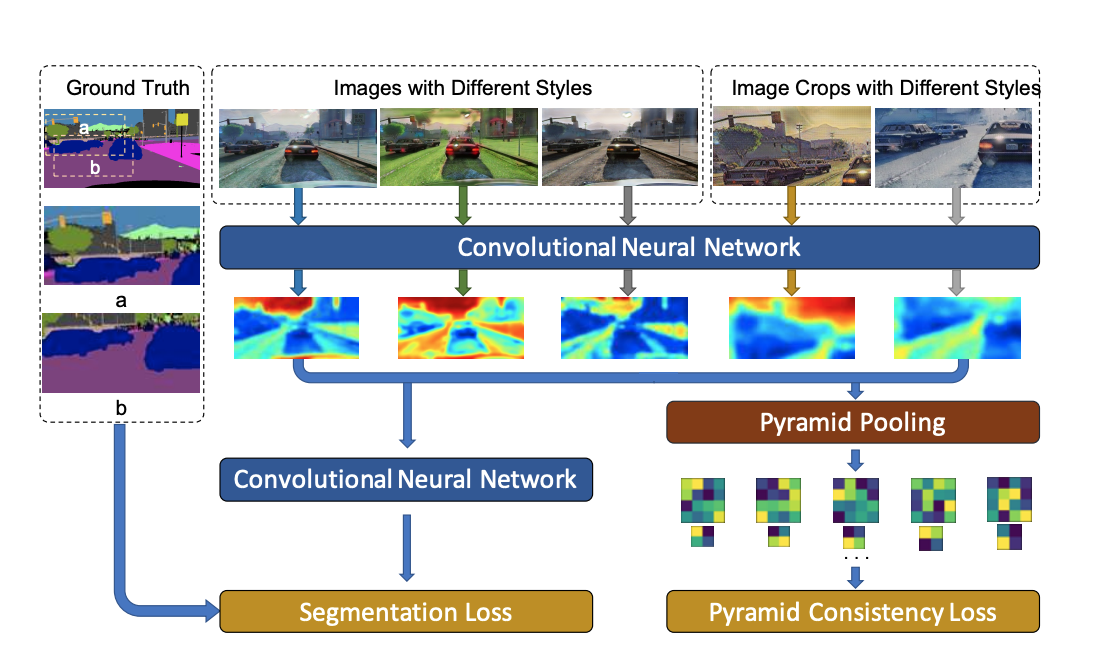
Domain Randomization and Pyramid Consistency: Simulation-to-Real Generalization without Accessing Target Domain Data
Xiangyu Yue,
Yang Zhang, Sicheng Zhao, Alberto Sangiovanni-Vincentelli, Kurt Keutzer, Boqing Gong
International Conference on Computer Vision (ICCV), 2019
PDF |
BibTex
|
|
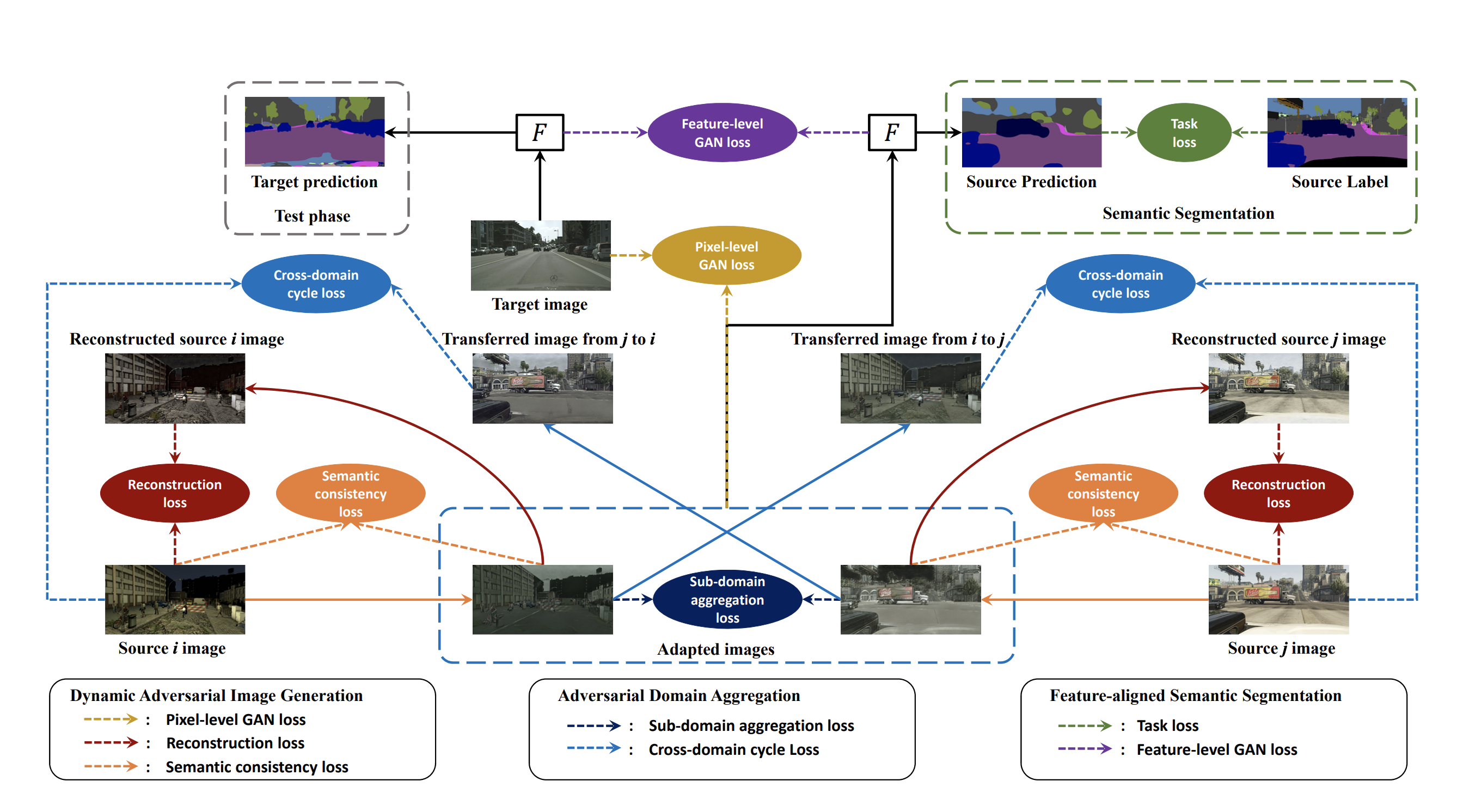
Multi-source Domain Adaptation for Semantic Segmentation
Sicheng Zhao*, Bo Li*,
Xiangyu Yue*,
Yang Gu, Pengfei Xu, Runbo Hu, Hua Chai, Kurt Keutzer (* indicates equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2019
PDF |
Code |
BibTex
|

|
Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud
Bichen Wu*, Xuanyu Zhou*, Sicheng Zhao*,
Xiangyu Yue,
Kurt Keutzer (* indicates equal contribution)
International Conference on Robotics and Automation (ICRA) 2019
PDF |
Code |
BibTex
|
|
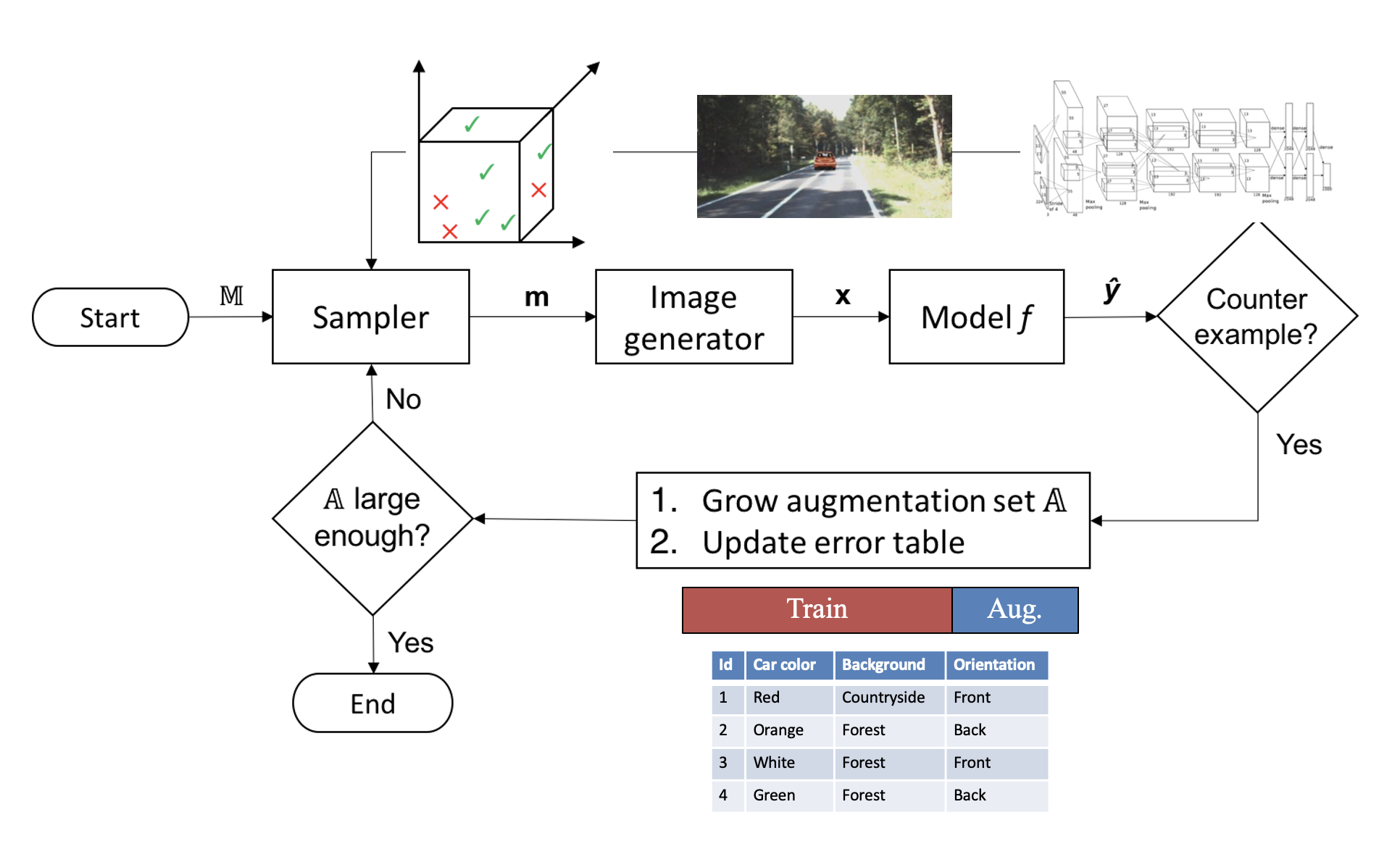
Counterexample-guided Data Augmentation
Tommaso Dreossi, Shromona Ghosh,
Xiangyu Yue,
Kurt Keutzer, Alberto Sangiovanni-Vincentelli, Sanjit A Seshia
International Joint Conference on Artificial Intelligence (IJCAI) 2018
PDF |
Code |
BibTex
|
|
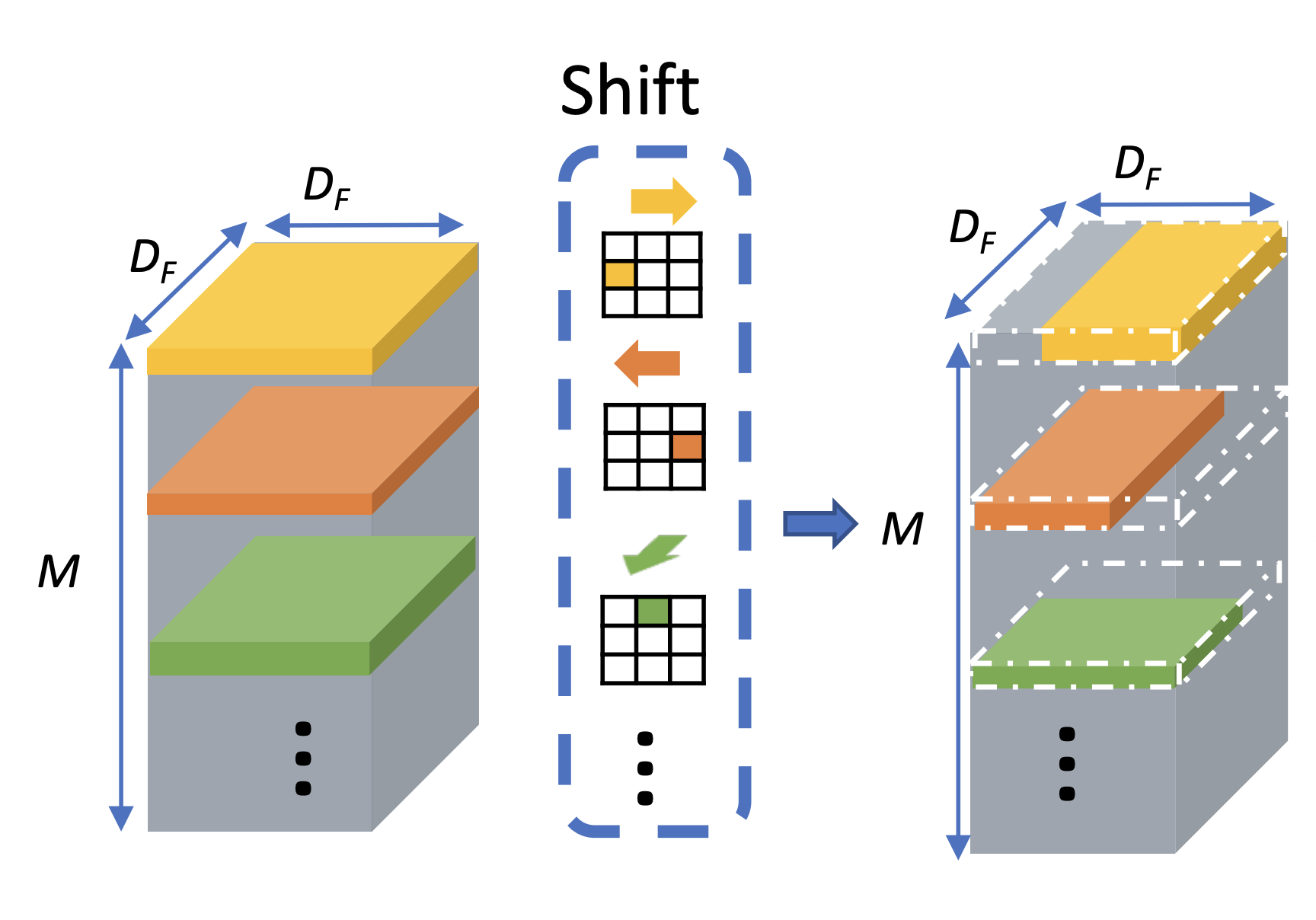
Shift: A Zero-flop, Zero-parameter Alternative to Apatial Convolutions
Bichen Wu,
Xiangyu Yue*,
Alvin Wan*, Peter Jin, Sicheng Zhao, Noah Golmant, Amir Gholaminejad, Joseph Gonzalez, Kurt Keutzer (* indicates equal contribution)
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018
PDF |
Code |
BibTex
|

|
A LiDAR Point Cloud Generator: from a Virtual World to Autonomous Driving
Xiangyu Yue,
Bichen Wu, Sanjit A Seshia, Kurt Keutzer, Alberto L Sangiovanni-Vincentelli
International Conference on Multimedia Retrieval (ICMR) 2018
PDF |
BibTex
|
|
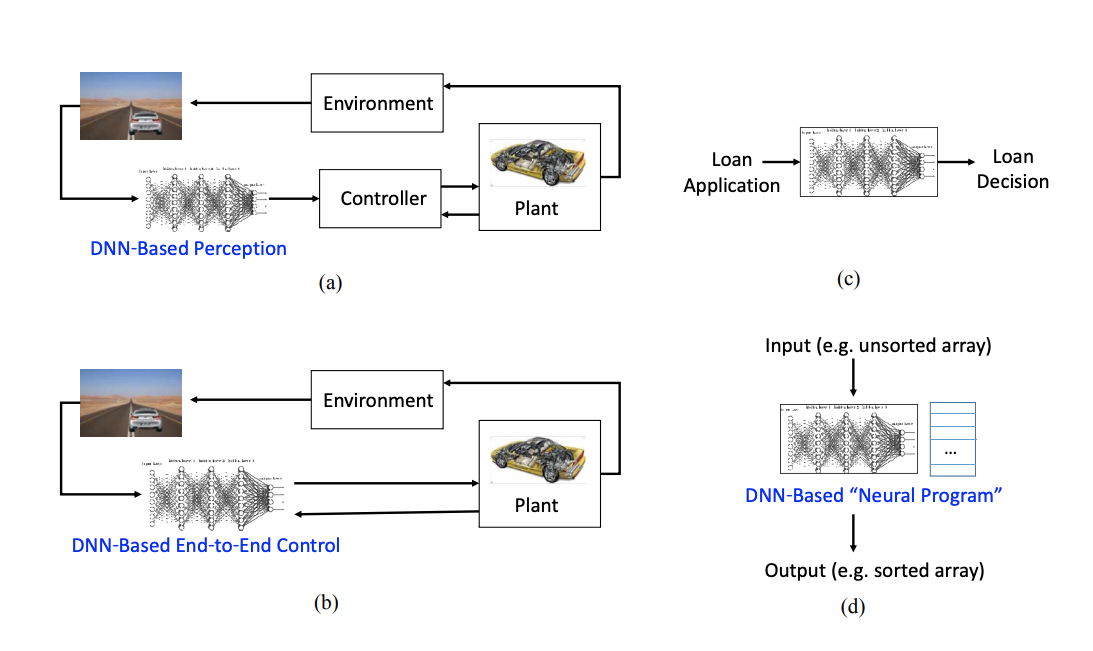
Formal Specification for Deep Neural Networks
Sanjit A Seshia, Ankush Desai, Tommaso Dreossi, Daniel J Fremont, Shromona Ghosh, Edward Kim, Sumukh Shivakumar, Marcell Vazquez-Chanlatte,
Xiangyu Yue
International Symposium on Automated Technology for Verification and Analysis (ATVA) 2018
PDF |
BibTex
|

|
SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-time Road-object Segmentation from 3d LiDAR Point Cloud
Bichen Wu, Alvin Wan,
Xiangyu Yue,
Kurt Keutzer
International Conference on Robotics and Automation (ICRA) 2018
PDF |
Video |
Code |
BibTex
|
