ECCV


European Conference on Computer Vision (ECCV), 2026
International Conference on Machine Learning (ICML), 2026
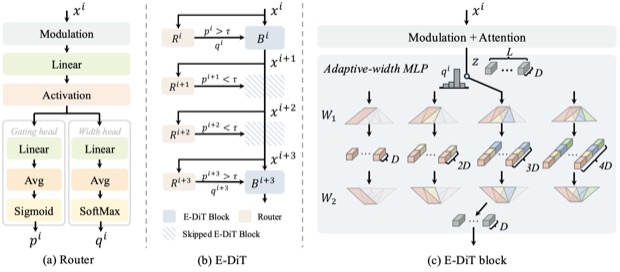

International Conference on Machine Learning (ICML), 2026
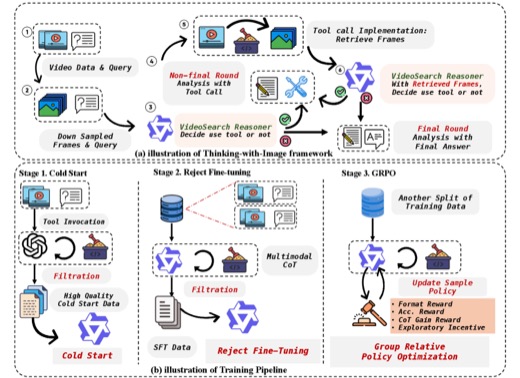
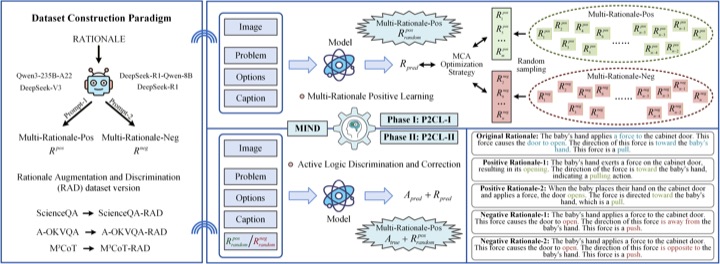
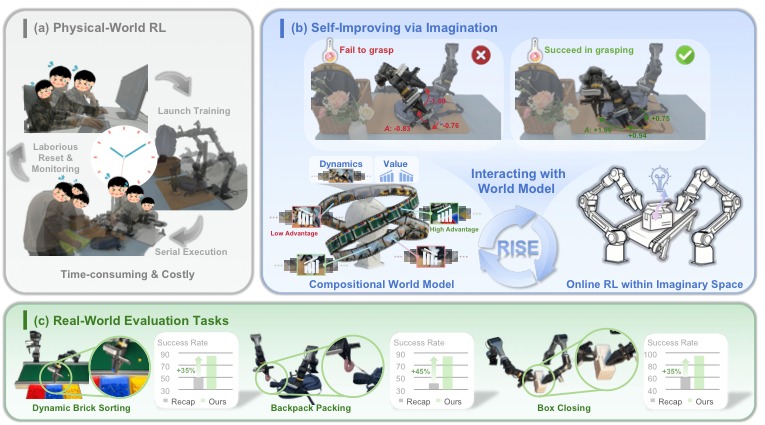
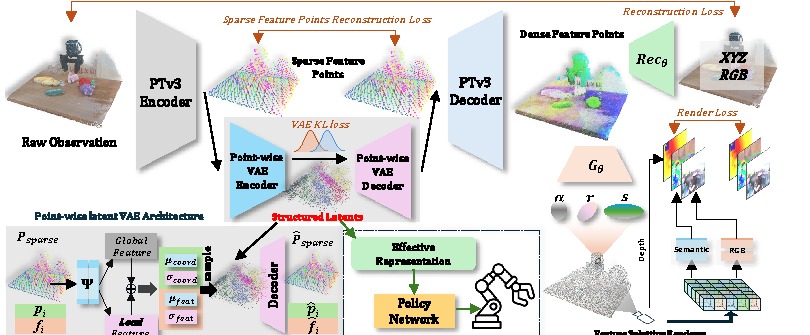
AAAI Conference on Artificial Intelligence (AAAI), 2026




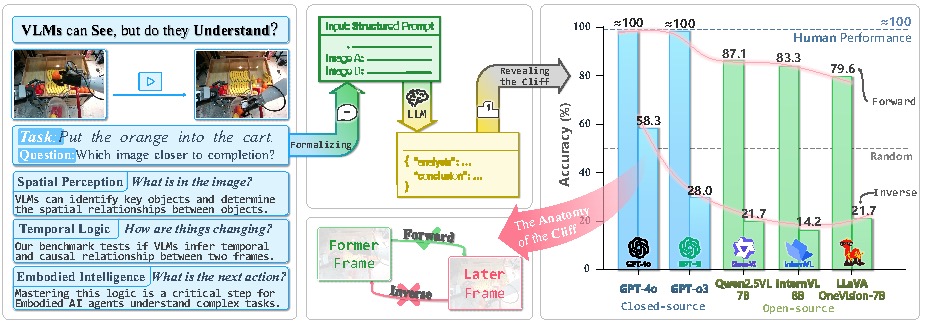
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026


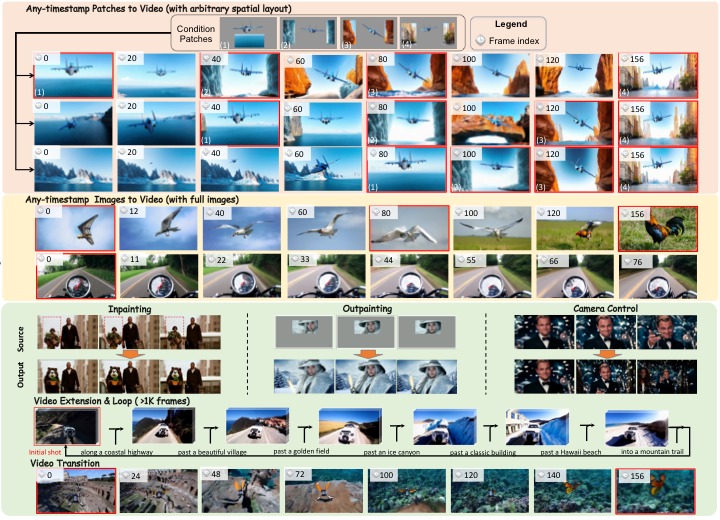
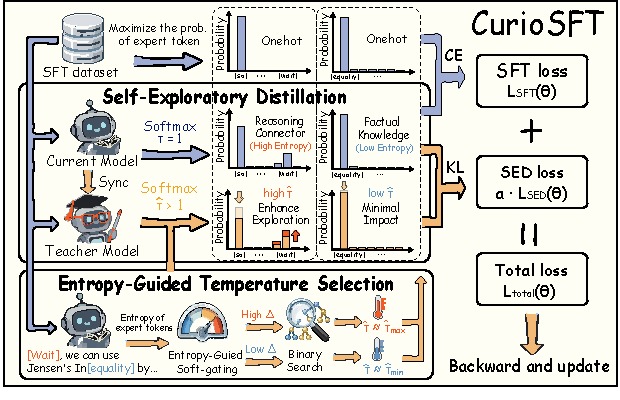
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Findings, 2026

International Conference on Learning Representations (ICLR), 2026
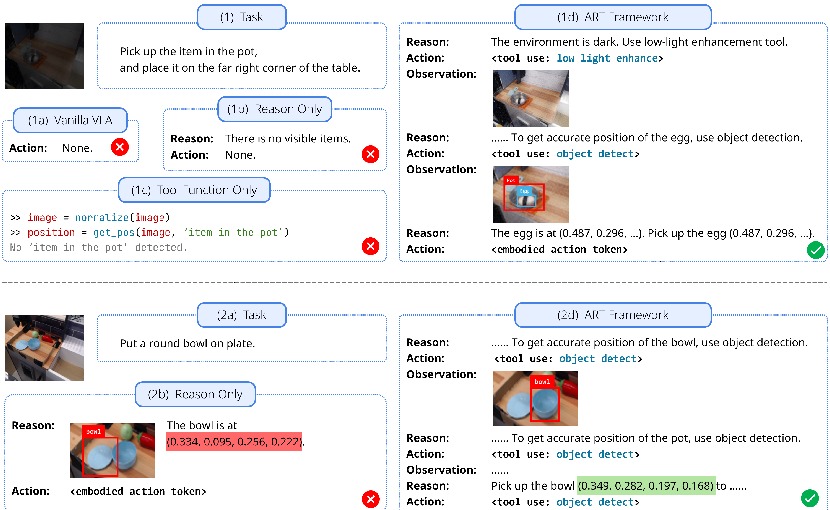
International Conference on Learning Representations (ICLR), 2026
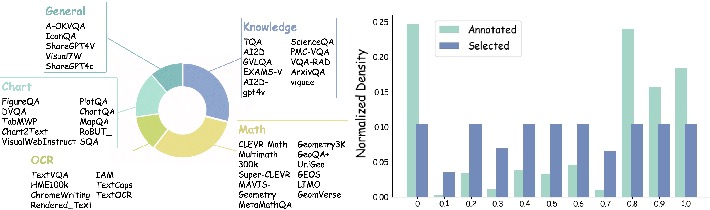
International Conference on Learning Representations (ICLR), 2026
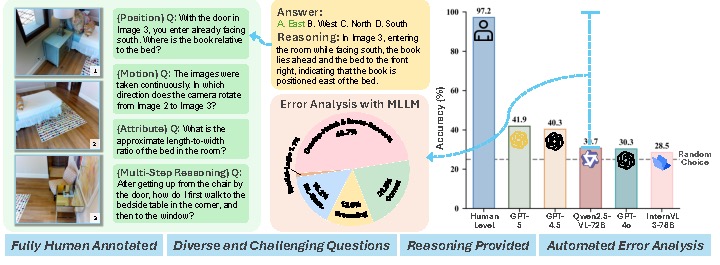
International Conference on Learning Representations (ICLR), 2026
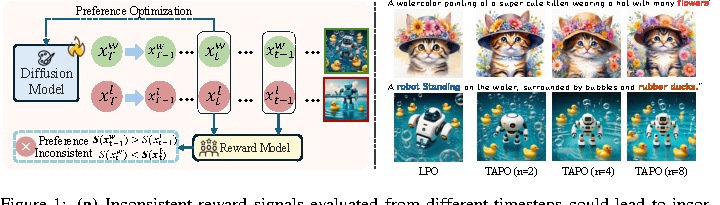
International Conference on Learning Representations (ICLR), 2026
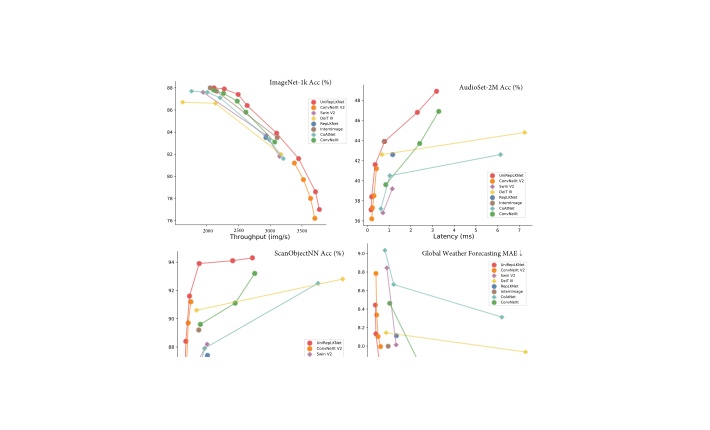

NeurIPS 2025 Most Influential Paper Top 10
Advances in Neural Information Processing Systems (NeurIPS), 2025
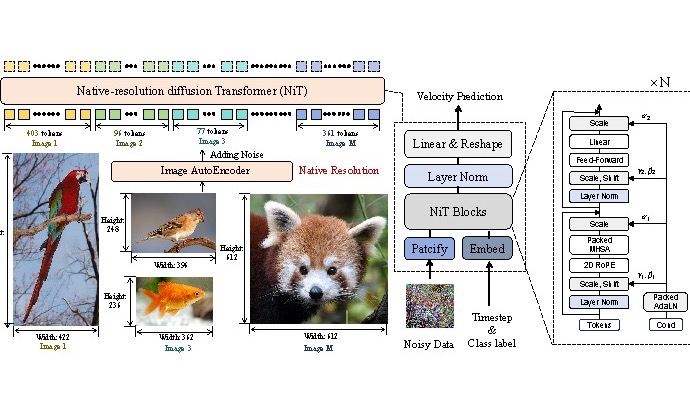
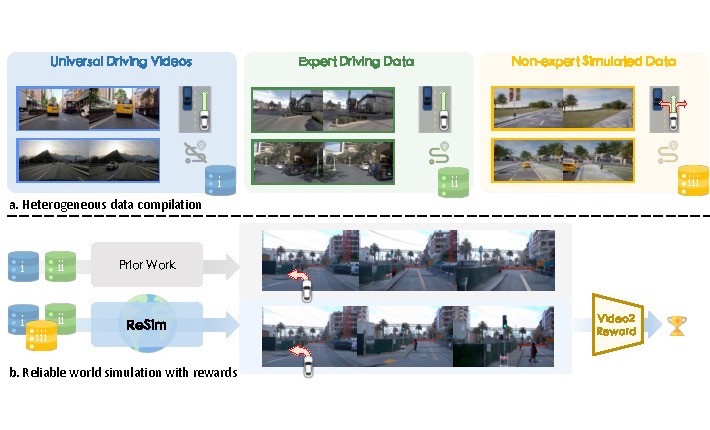


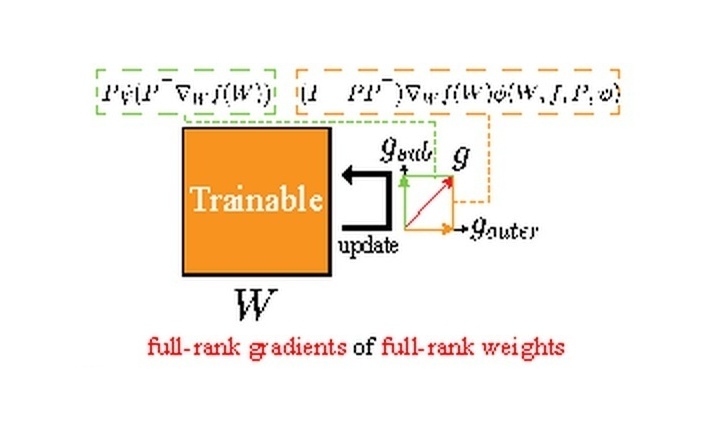
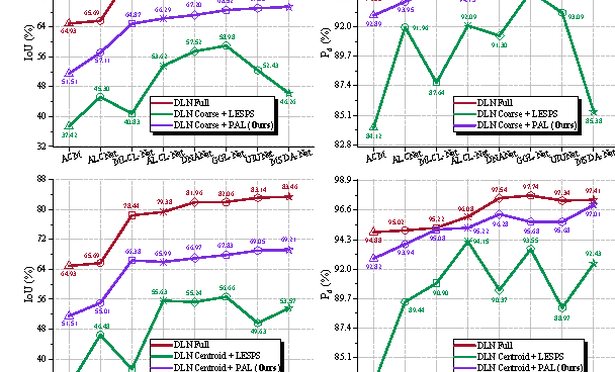
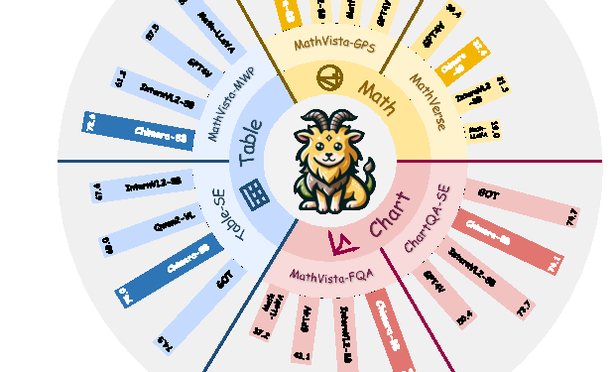
IEEE/CVF International Conference on Computer Vision (ICCV), 2025

IEEE/CVF International Conference on Computer Vision (ICCV), 2025

IEEE/CVF International Conference on Computer Vision (ICCV), 2025

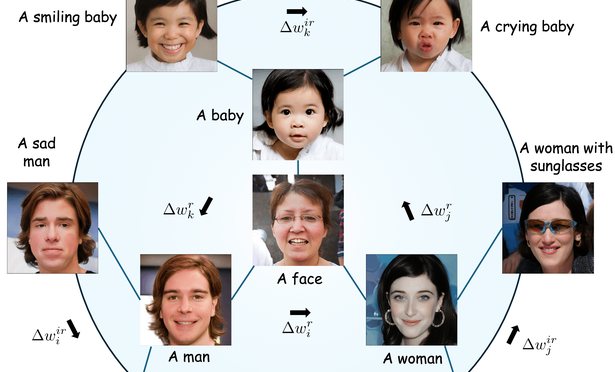
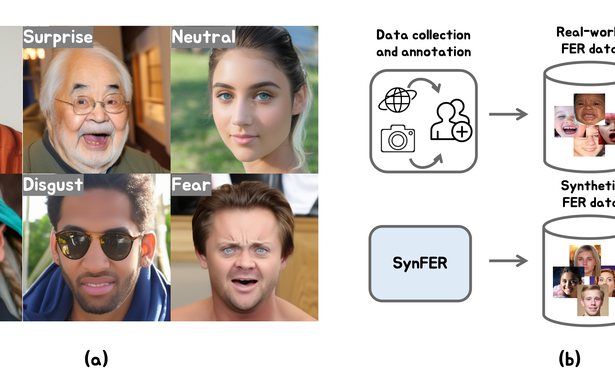
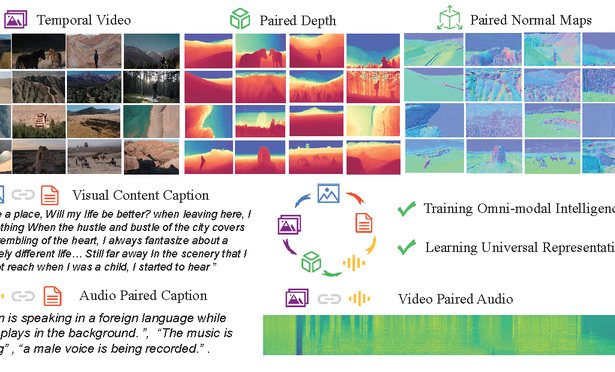
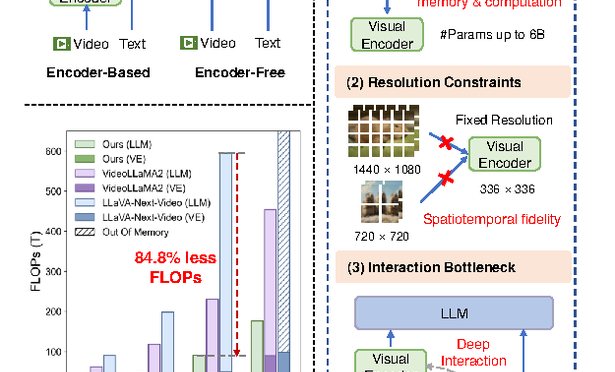
IEEE/CVF International Conference on Computer Vision (ICCV), 2025